Lecture 7: Gaussian Discriminant Analysis
Contents
Lecture 7: Gaussian Discriminant Analysis#
The previous lecture introduced generative modeling and Naive Bayes. In this lecture, we will see a second learning algorithm based on a generative modeling called Gaussian Discriminant Analysis.
7.1. Revisiting Generative Models#
Let’s first review generative models and how they differ from discriminative models. We will illustrate these differences on a simple classification task.
7.1.1. The Iris Flowers Dataset#
As a running example for this lecture, we are going to again use the Iris flower dataset (R. A. Fisher, 1936). Recall that our task is to classify subspecies of Iris flowers based on their measurements.
First, let’s load the dataset and print the examples from the dataset.
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
from sklearn import datasets
# Load the Iris dataset
iris = datasets.load_iris(as_frame=True)
# print part of the dataset
iris_X, iris_y = iris.data, iris.target
pd.concat([iris_X, iris_y], axis=1).head()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
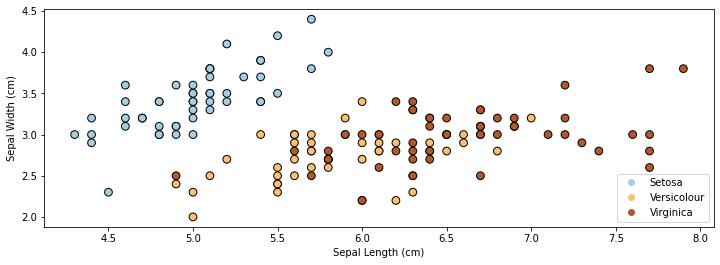
If we only consider the first two feature columns, we can visualize the dataset in 2D.
# https://scikit-learn.org/stable/auto_examples/neighbors/plot_classification.html
%matplotlib inline
from matplotlib import pyplot as plt
plt.rcParams['figure.figsize'] = [12, 4]
# create 2d version of dataset
X = iris_X.to_numpy()[:,:2]
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
# Plot also the training points
p1 = plt.scatter(X[:, 0], X[:, 1], c=iris_y, edgecolor='k', s=60, cmap=plt.cm.Paired)
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Sepal Width (cm)')
plt.legend(handles=p1.legend_elements()[0], labels=['Setosa', 'Versicolour', 'Virginica'], loc='lower right')
<matplotlib.legend.Legend at 0x7f7b6107ed00>
7.1.2. Review: Discriminative Models#
Most models we have seen thus far have been discriminative:
They directly transform \(x\) into a score for each class \(y\) (e.g., via the formula \(y=\sigma(\theta^\top x)\))
They can be interpreted as defining a conditional probability \(P_\theta(y|x)\)
For example, logistic regression is a binary classification algorithm which uses a model \(f_\theta : \mathcal{X} \to [0,1]\) of the form
where \(\sigma(z) = \frac{1}{1 + \exp(-z)}\) is the sigmoid or logistic function.
The logistic model defines (“parameterizes”) a probability distribution \(P_\theta(y|x) : \mathcal{X} \times \mathcal{Y} \to [0,1]\) as follows:
Logistic regression optimizes the following objective defined over a binary classification dataset \(\mathcal{D} = \{(x^{(1)}, y^{(1)}), (x^{(2)}, y^{(2)}), \ldots, (x^{(n)}, y^{(n)})\}\).
This objective is also often called the log-loss, or cross-entropy. This asks the model to ouput a large score \(\sigma(\theta^\top x^{(i)})\) (a score that’s close to one) if \(y^{(i)}=1\), and a score that’s small (close to zero) if \(y^{(i)}=0\).
Now, let’s train logistic/softmax regression on this dataset.
from matplotlib import pyplot as plt
plt.rcParams['figure.figsize'] = [12, 4]
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression(C=1e5)
# Create an instance of Logistic Regression Classifier and fit the data.
X = iris_X.to_numpy()[:,:2]
# rename class two to class one
Y = iris_y.copy()
logreg.fit(X, Y)
LogisticRegression(C=100000.0)
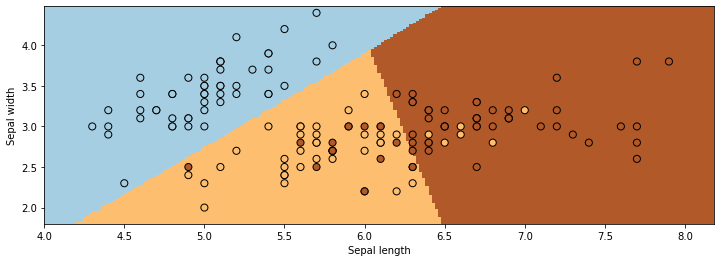
We visualize the regions predicted to be associated with the blue, brown, and yellow classes and the lines between them are the decision boundaries.
xx, yy = np.meshgrid(np.arange(4, 8.2, .02), np.arange(1.8, 4.5, .02))
Z = logreg.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
# Plot also the training points
plt.scatter(X[:, 0], X[:, 1], c=Y, edgecolors='k', cmap=plt.cm.Paired, s=50)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()
7.1.3. Review: Generative Models#
Another approach to classification is to use generative models.
A generative approach first defines a probabilistic model of \(x\) for each class:
\(P_\theta(x | y=k)\) assigns a probability to each \(x\) depending on how likely it is to originate from class \(k\). The \(x\) that are deemed to be more likely to be of class \(k\) get a higher probability.
A generative model also requires specifying a class probability \(P_\theta(y=k)\) that encodes our prior beliefs
These are often just the % of each class in the data.
In the context of Iris flower classification, we would fit three models on a labeled corpus:
We would also define priors \(P_\theta(y=\text{0}), P_\theta(y=\text{1}),P_\theta(y=\text{2})\).
\(P_\theta(x | y=k)\) scores each \(x\) based on how much it looks like class \(k\).
7.1.3.1. Probabilistic Interpretations#
A generative model defines \(P_\theta(x|y)\) and \(P_\theta(y)\), thus it also defines a distribution of the form \(P_\theta(x,y)\).
Discriminative models don’t define any probability over the \(x\)’s. Generative models do.
We can learn a generative model \(P_\theta(x, y)\) by maximizing the likelihood:
This says that we should choose parameters \(\theta\) such that the model \(P_\theta\) assigns a high probability to each training example \((x^{(i)}, y^{(i)})\) in the dataset \(\mathcal{D}\).
7.2. Gaussian Mixture Models#
We are now going to introduce a second generative model called the Gaussian mixture model and see why it might be better than the Naive Bayes model introduced in the previous lecture.
7.2.1. Review and Motivation#
Let’s start by reminding ourselves of the formulas for two important probability distributions.
7.2.1.1. Review of Distributions#
Categorical Distribution#
A Categorical distribution with parameters \(\theta\) is a probability over \(K\) discrete outcomes \(x \in \{1,2,...,K\}\):
When \(K=2\) this is called the Bernoulli.
Normal (Gaussian) Distribution#
A multivariate normal distribution \(P_\theta(x) : \mathcal{X} \to [0,1]\) with parameters \(\theta = (\mu, \Sigma)\) is a probability over a \(d\)-dimensional \(x \in \mathbb{R}^d\)
In one dimension, this reduces to \(\frac{1}{\sqrt{2 \pi}\sigma} \exp\left(-\frac{(x - \mu)^2}{2\sigma^2} \right)\).
This what the density of a Normal distribution looks like in 2D:
This is how we can visualize it in a 2D plane:
7.2.1.2. A Generative Model for Iris Flowers#
To define a generative model for Iris flowers, we need to define three probabilities:
We also define priors \(P_\theta(y=\text{0}), P_\theta(y=\text{1}), P_\theta(y=\text{2})\).
Each model \(P_\theta(x | y=k)\) scores \(x\) based on how much it looks like class \(k\). The inputs \(x\) are vectors of features for the flowers.
How do we choose \(P_\theta(x|y=k)\)? One possible approach could be to use Naive Bayes. However Naive Bayes defines \(P_\theta(x|y=k)\) as a product of Bernoulli distributions. These are only defined for vectors of discrete binary inputs \(x\). In the iris flower example, \(x\) consists of flower measurements, which are continuous numbers. Hence, we need to define a different family of models \(P_\theta(x|y=k)\).
7.2.2. Gaussian Mixture Model#
A Gaussian mixture model (GMM) \(P_\theta(x,y)\) is defined for real-valued data \(x \in \mathbb{R}^d\).
The probability of the data \(x\) for each class is a multivariate Gaussian
The probability over \(y\) is Categorical: \(P_\theta(y=k) = \phi_k\).
Thus the full set of parameter \(\theta\) consists of the prior parameters \(\vec\phi = (\phi_1,...,\phi_K)\) and \(K\) tuples of per-class Gaussian parameters \((\mu_k, \Sigma_k)\).
7.2.2.1. GMMs Are Mixtures of Gaussians Distributions#
The GMM is an example of a mixture of \(K\) distributions with mixing weights \(\phi_k = P(y=k)\):
The distribution \(P_\theta(y=k) = \pi_k\) encodes the mixture weights.
The distribution \(P_\theta(x|y=k) = P_k(x; \theta_k)\) encodes the \(k\)-th mixed distribution.
Mixtures can express distributions that a single mixture component can’t:
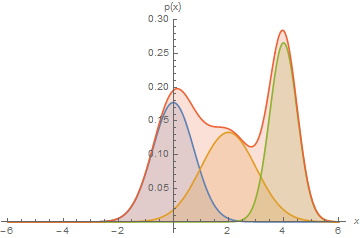
Here, we have a mixture of 3 Gaussians.
Mixtures of Gaussians fit more complex distributions than one Gaussian.
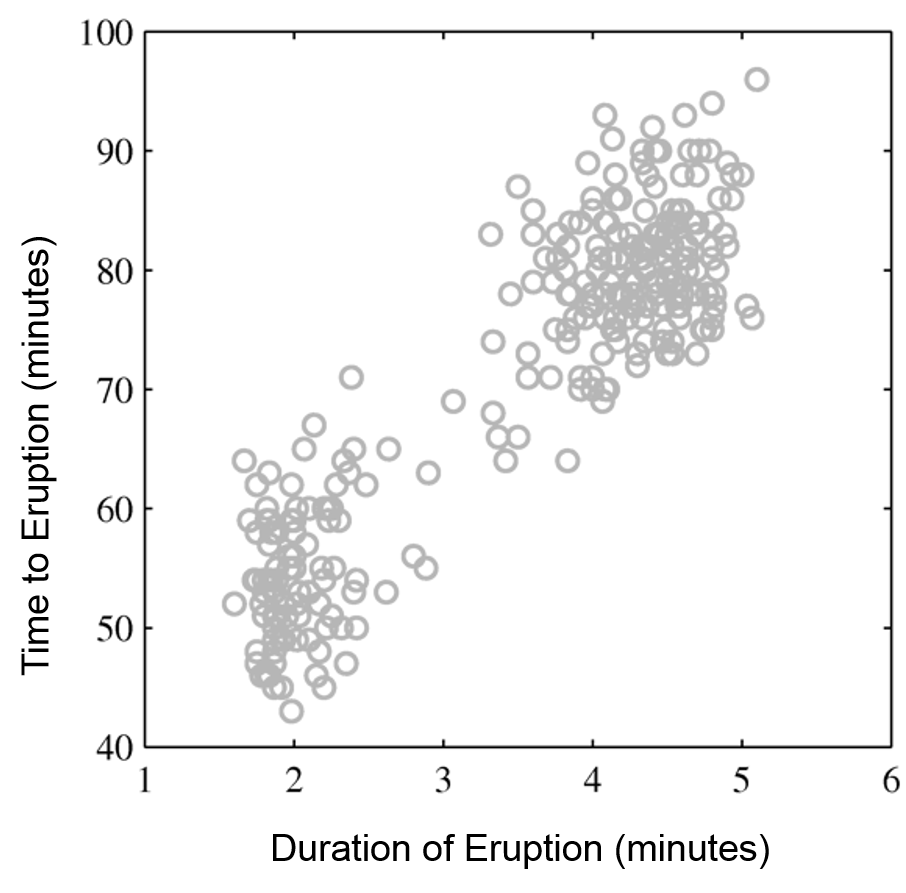
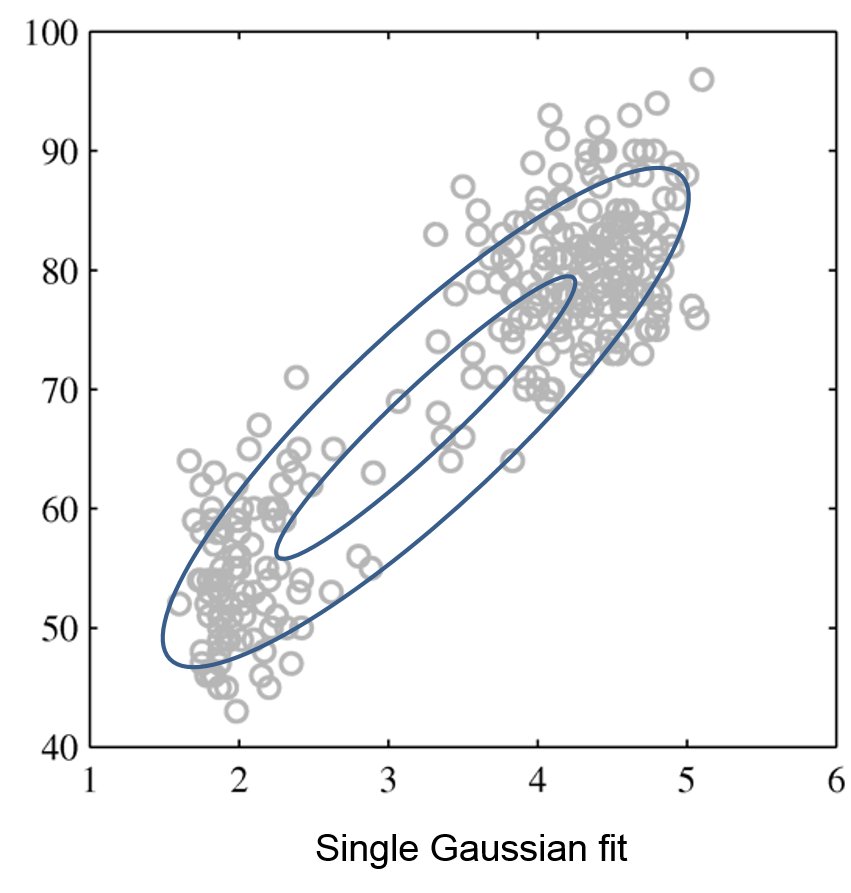
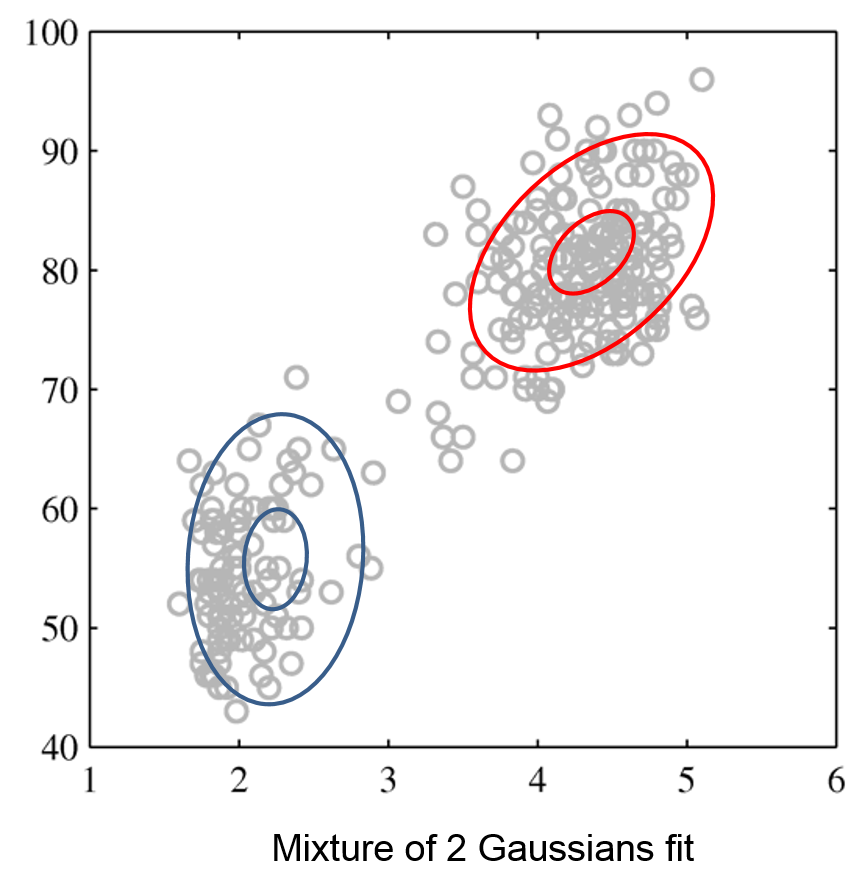
The figures below illustrate how the mixture of two Gaussians can model the distribution composed of two separate clusters, which are poorly represented by a single Gaussian.
Raw data |
Single Gaussian |
Mixture of Gaussians |
|---|---|---|
|
|
|
A Gaussian mixture model also defines a story for how the data was generated. To obtain a data point,
First, we sample a class \(y \sim \text{Categorical}(\phi_1, \phi_2, ..., \phi_K)\) with class proportions given by the \(\phi_k\).
Then, we sample an \(x\) from a Gaussian distribution \(\mathcal{N}(\mu_k, \Sigma_k)\) specific to that class.
Such a story can be constructed for most generative algorithms and helps understand them.
7.2.2.2. Predictions Out of Gaussian Mixture Models#
Given a trained model \(P_\theta (x,y) = P_\theta (x | y) P_\theta (y)\), we can look at the posterior probability
of a point \(x\) belonging to class \(k\).
7.3. Gaussian Discriminant Analysis#
Next, we will use GMMs as the basis for a new generative classification algorithm, Gaussian Discriminant Analysis (GDA).
7.3.1. Review: Maximum Likelihood Learning#
We can learn a generative model \(P_\theta(x, y)\) by maximizing the maximum likelihood:
This seeks to find parameters \(\theta\) such that the model assigns high probability to the training data.
Let’s use maximum likelihood to fit the Guassian Discriminant model. Note that model parameters \(\theta\) are the union of the parameters of each sub-model:
Mathematically, the components of the model \(P_\theta(x,y)\) are as follows.
7.3.2. Optimizing the Log Likelihood#
Given a dataset \(\mathcal{D} = \{(x^{(i)}, y^{(i)})\mid i=1,2,\ldots,n\}\), we want to optimize the log-likelihood \(\ell(\theta)\):
In equality #2, we use the fact that \(P_\theta(x,y)=P_\theta(y) P_\theta(x|y)\); in the third one, we change the order of summation.
Each \(\mu_k, \Sigma_k\) for \(k=1,2,\ldots,K\) is found in only the following subset of the terms that comprise the full log-likelihood definition:
Thus, optimization over \(\mu_k, \Sigma_k\) can be carried out independently of all the other parameters by just looking at these terms.
Similarly, optimizing for \(\vec \phi = (\phi_1, \phi_2, \ldots, \phi_K)\) only involves a small subset of all the terms that comprise the full log-likelihood:
7.3.2.1. Learning the Parameters \(\phi\)#
Let’s first consider the optimization over \(\vec \phi = (\phi_1, \phi_2, \ldots, \phi_K)\).
We have \(n\) datapoints. Each point has a label \(k\in\{1,2,...,K\}\).
Our model is a categorical and assigns a probability \(\phi_k\) to each outcome \(k\in\{1,2,...,K\}\).
We want to infer \(\phi_k\) assuming our dataset is sampled from the model.
What are the maximum likelihood \(\phi_k\) that are most likely to have generated our data? Intuitively, the maximum likelihood class probabilities \(\phi\) should just be the class proportions that we see in the data.
Note that this is analogous to an earlier example in which we used the principle of maximum likelihood to estimate the probability of the biased coin falling heads: that probability was equal to the frequency of observing heads in our dataset. Similarly, the maximum likelihood estimate of sampling a datapoint with class \(k\) corresponds to the fraction of datapoints in our training set that are labeled as class \(k\).
Let’s calculate this formally. Our objective \(J(\vec \phi)\) equals
Taking the partial derivative with respect to \(\phi_k\):
Setting this derivative to zero, we obtain
for each \(k\), where \(n_k = |\{i : y^{(i)} = k\}|\) is the number of training targets with class \(k\).
Thus, the maximum likelihood set of parameters \(\phi_k\) must satisfy the above constraint. Because we know that the set of parameters \(\sum_{l=1}^K \phi_l\) must also sum to one, we plug this fact into the above equation to conclude that:
Thus, the optimal \(\phi_k\) is just the proportion of data points with class \(k\) in the training set!
7.3.2.2. Learning the Parameters \(\mu_k, \Sigma_k\)#
Next, let’s look at the maximum likelihood term
over the Gaussian parameters \(\mu_k, \Sigma_k\).
Our dataset are all the points \(x\) for which \(y=k\).
We want to learn the mean and variance \(\mu_k, \Sigma_k\) of a normal distribution that generates this data.
What is the maximum likelihood \(\mu_k, \Sigma_k\) in this case?
Computing the derivative and setting it to zero (the mathematical proof is left as an exercise to the reader), we obtain closed form solutions:
These are just the observed means and covariances within each class.
7.3.2.3. Querying the Model#
How do we ask the model for predictions? As discussed earlier, we can apply Bayes’ rule:
Thus, we can estimate the probability of \(x\) and under each \(P_\theta(x|y=k)P(y=k)\) and choose the class that explains the data best.
7.3.3. Algorithm: Gaussian Discriminant Analysis (GDA)#
The above procedure describes an example of generative models—Gaussian Discriminant Analysis (GDA). We can succinctly define GDA in terms of the algorithm components.
Type: Supervised learning (multi-class classification)
Model family: Mixtures of Gaussians.
Objective function: Log-likelihood.
Optimizer: Closed form solution.
7.3.3.1. Example: Iris Flower Classification#
Let’s see how this approach can be used in practice on the Iris dataset.
We will learn the maximum likelihood GDA parameters
We will compare the outputs to the true predictions.
Let’s first start by computing the model parameters on our dataset. It only takes a few lines of code!
# we can implement these formulas over the Iris dataset
d = 2 # number of features in our toy dataset
K = 3 # number of classes
n = X.shape[0] # size of the dataset
# these are the shapes of the parameters
mus = np.zeros([K,d])
Sigmas = np.zeros([K,d,d])
phis = np.zeros([K])
# we now compute the parameters
for k in range(3):
X_k = X[iris_y == k]
mus[k] = np.mean(X_k, axis=0)
Sigmas[k] = np.cov(X_k.T)
phis[k] = X_k.shape[0] / float(n)
# print out the means
print(mus)
[[5.006 3.428]
[5.936 2.77 ]
[6.588 2.974]]
We can compute predictions using Bayes’ rule.
# we can implement this in numpy
def gda_predictions(x, mus, Sigmas, phis):
"""This returns class assignments and p(y|x) under the GDA model.
We compute \arg\max_y p(y|x) as \arg\max_y p(x|y)p(y)
"""
# adjust shapes
n, d = x.shape
x = np.reshape(x, (1, n, d, 1))
mus = np.reshape(mus, (K, 1, d, 1))
Sigmas = np.reshape(Sigmas, (K, 1, d, d))
# compute probabilities
py = np.tile(phis.reshape((K,1)), (1,n)).reshape([K,n,1,1])
pxy = (
np.sqrt(np.abs((2*np.pi)**d*np.linalg.det(Sigmas))).reshape((K,1,1,1))
* -.5*np.exp(
np.matmul(np.matmul((x-mus).transpose([0,1,3,2]), np.linalg.inv(Sigmas)), x-mus)
)
)
pyx = pxy * py
return pyx.argmax(axis=0).flatten(), pyx.reshape([K,n])
idx, pyx = gda_predictions(X, mus, Sigmas, phis)
print(idx)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 1 0 0 0 0 0 0 0 0 2 2 2 1 2 1 2 1 2 1 1 1 1 1 1 2 1 1 1 1 1 1 2 1
2 2 2 2 1 1 1 1 1 1 1 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 2 1 2 2 2 2 1 2 2 2 2
2 2 1 1 2 2 2 2 1 2 1 2 1 2 2 1 1 2 2 2 2 2 1 1 2 2 2 1 2 2 2 1 2 2 2 2 2
2 1]
We visualize the decision boundaries like we did earlier. The figure illustrates that three Gaussians learned through Gaussian Discriminant Analysis split the data points from three classes reasonably.
from matplotlib.colors import LogNorm
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02), np.arange(y_min, y_max, .02))
Z, pyx = gda_predictions(np.c_[xx.ravel(), yy.ravel()], mus, Sigmas, phis)
logpy = np.log(-1./3*pyx)
# Put the result into a color plot
Z = Z.reshape(xx.shape)
contours = np.zeros([K, xx.shape[0], xx.shape[1]])
for k in range(K):
contours[k] = logpy[k].reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
for k in range(K):
plt.contour(xx, yy, contours[k], levels=np.logspace(0, 1, 1))
# Plot also the training points
plt.scatter(X[:, 0], X[:, 1], c=iris_y, edgecolors='k', cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()
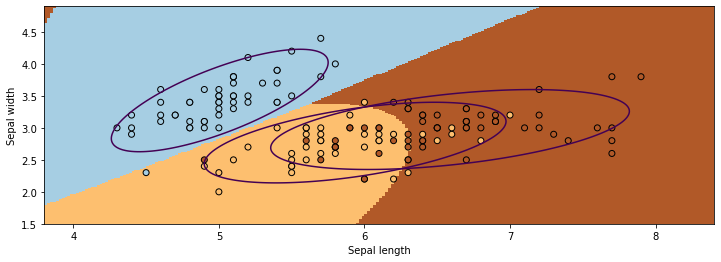
7.3.3.2. Special Cases of GDA#
Many important generative algorithms are special cases of Gaussian Discriminative Analysis
Linear discriminant analysis (LDA): all the covariance matrices \(\Sigma_k\) take the same value.
Gaussian Naive Bayes: all the covariance matrices \(\Sigma_k\) are diagonal.
Quadratic discriminant analysis (QDA): another term for GDA.
7.4. Discriminative vs. Generative Algorithms#
We conclude our lectures on generative algorithms by revisiting the question of how they compare to discriminative algorithms.
7.4.1. Linear Discriminant Analysis#
When the covariances \(\Sigma_k\) in GDA are equal, we have an algorithm called Linear Discriminant Analysis or LDA. The probability of the data \(x\) for each class is a multivariate Gaussian with the same covariance \(\Sigma\).
The probability over \(y\) is Categorical: \(P_\theta(y=k) = \phi_k\).
Let’s apply this algorithm on the Iris flower dataset. We compute the model parameters similarly to how we did for GDA.
# we can implement these formulas over the Iris dataset
d = 2 # number of features in our toy dataset
K = 3 # number of classes
n = X.shape[0] # size of the dataset
# these are the shapes of the parameters
mus = np.zeros([K,d])
Sigmas = np.zeros([K,d,d])
phis = np.zeros([K])
# we now compute the parameters
for k in range(3):
X_k = X[iris_y == k]
mus[k] = np.mean(X_k, axis=0)
Sigmas[k] = np.cov(X.T) # this is now X.T instead of X_k.T
phis[k] = X_k.shape[0] / float(n)
# print out the means
print(mus)
[[5.006 3.428]
[5.936 2.77 ]
[6.588 2.974]]
We can compute predictions using Bayes’ rule.
# we can implement this in numpy
def gda_predictions(x, mus, Sigmas, phis):
"""This returns class assignments and p(y|x) under the GDA model.
We compute \arg\max_y p(y|x) as \arg\max_y p(x|y)p(y)
"""
# adjust shapes
n, d = x.shape
x = np.reshape(x, (1, n, d, 1))
mus = np.reshape(mus, (K, 1, d, 1))
Sigmas = np.reshape(Sigmas, (K, 1, d, d))
# compute probabilities
py = np.tile(phis.reshape((K,1)), (1,n)).reshape([K,n,1,1])
pxy = (
np.sqrt(np.abs((2*np.pi)**d*np.linalg.det(Sigmas))).reshape((K,1,1,1))
* -.5*np.exp(
np.matmul(np.matmul((x-mus).transpose([0,1,3,2]), np.linalg.inv(Sigmas)), x-mus)
)
)
pyx = pxy * py
return pyx.argmax(axis=0).flatten(), pyx.reshape([K,n])
idx, pyx = gda_predictions(X, mus, Sigmas, phis)
print(idx)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 1 0 0 0 0 0 0 0 0 2 2 2 1 2 1 2 1 2 1 1 1 1 1 1 2 1 1 1 1 2 1 1 1
2 2 2 2 1 1 1 1 1 1 1 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 2 2 2 2 1 2 1 2 2
1 2 1 1 2 2 2 2 1 2 1 2 1 2 2 1 1 2 2 2 2 2 1 1 2 2 2 1 2 2 2 1 2 2 2 1 2
2 1]
We visualize predictions like we did earlier.
from matplotlib.colors import LogNorm
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02), np.arange(y_min, y_max, .02))
Z, pyx = gda_predictions(np.c_[xx.ravel(), yy.ravel()], mus, Sigmas, phis)
logpy = np.log(-1./3*pyx)
# Put the result into a color plot
Z = Z.reshape(xx.shape)
contours = np.zeros([K, xx.shape[0], xx.shape[1]])
for k in range(K):
contours[k] = logpy[k].reshape(xx.shape)
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
# Plot also the training points
plt.scatter(X[:, 0], X[:, 1], c=iris_y, edgecolors='k', cmap=plt.cm.Paired)
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.show()
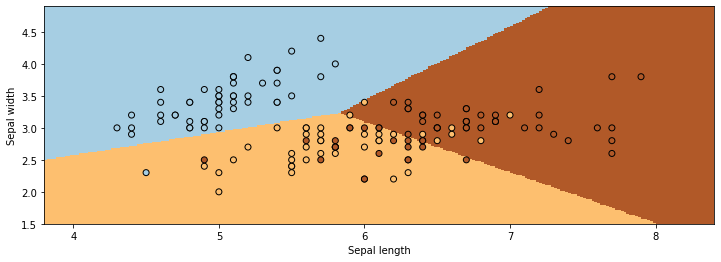
Linear Discriminant Analysis outputs decision boundaries that are linear, just like Logistic/Softmax Regression. Softmax or Logistic regression also produce linear boundaries. Is this a coincidence?
7.4.1.1. What Is the LDA Model Class?#
We can derive an analytic formula for \(P_\theta(y|x)\) in a Bernoulli Naive Bayes or LDA model when \(K=2\). After some algebra, we can show that
for some set of parameters \(\gamma\) (whose expression can be derived from \(\theta\)).
This is the same form as Logistic Regression! Does it mean that the two sets of algorithms are equivalent?
No! They assume the same model class \(\mathcal{M}\), they use a different objective \(J\) to select a model in \(\mathcal{M}\). More specifically, we can make the following conclusions:
Bernoulli Naive Bayes or LDA assumes a logistic form for \(P(y|x)\). But the converse is not true: logistic regression does not assume a NB or LDA model for \(P(x,y)\).
Generative models make stronger modeling assumptions. If these assumptions hold true, the generative models will perform better.
But if they don’t, logistic regression will be more robust to outliers and model misspecification, and achieve higher accuracy.
7.4.2. Generative Models vs. Discriminative Models#
Finally, we are revisiting the question of when we want to use generative models or discriminative models.
Discriminative algorithms are deservingly very popular.
Most state-of-the-art algorithms for classification are discriminative (including neural nets, boosting, SVMs, etc.)
They are often more accurate because they make fewer modeling assumptions.
But generative models can do things that discriminative models can’t do.
Generation: we can sample \(x \sim p(x|y)\) to generate new data (images, audio).
Missing value imputation: if \(x_j\) is missing, we infer it using \(p(x|y)\).
Outlier detection: we may detect via \(p(x')\) if \(x'\) is an outlier.
Scalability: Simple formulas for maximum likelihood parameters.
And generative algorithms also have many other advantages:
Can do more than just prediction: generation, fill-in missing features, etc.
Can include extra prior knowledge; if prior knowledge is correct, model will be more accurate.
Often have closed-form solutions, hence are faster to train.