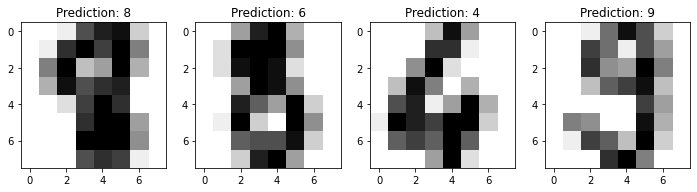Lecture 1: Introduction to Machine Learning
Contents
Lecture 1: Introduction to Machine Learning#
Welcome to Applied Machine Learning—an open online version of CS 5785, a course taught at Cornell University and Cornell Tech.
Our goal for this first lecture will be provide an overview of the course, and work towards a first definition of machine learning. In the final part of the lecture, we will cover important logistical details that you should know when taking the course.
1.1. What is Machine Learning?#
Below are three snippets from the press that pertain to machine learning (ML) and the related field of artificial intelligence (AI).
 |
 |
 |
The image on the left is from the cover of the journal Nature. It is meant to illustrate that ML is fundamentally a field of science. In recent years, this field has seen rapid advances, such as this famous 2016 breakthrough from Google Deepmind, in which an ML-based system called AlphaGo became the world champion at the game of Go—a feat that was previously thought to be decades away.
In the middle, we see a interview by Wired magazine with Barrack Obama on ML and AI. Obama discusses the impact of AI on topics like unemployment and inequality. It is meant to illustrate that ML is not only a scientific endeavor, but also a field that is having a profound impact on society and policy.
Our third snippet is the blog post announcing ChatGPT, and is meant to show that AI not science and policy, but enables the creation of useful tools. Assistants like ChatGPT will have an increasingly large impact on the automation of various aspects of work and of our daily lives.
1.1.1. Examples of ML in Everyday Life#
While ChatGPT is a particularly prominent example of a system powered by machine learning, there exist many other ways in which machine learning is deployed around us. In fact, you may have interacted with ML-based systems today without even realizing it.
Let’s look at a few examples and gradually work our way towards a precise definition of machine learning.
Search Engines#
Machine learning is used in search engines to parse queries and determine their intent. Another set of ML algorithms is then used to retrieve the information relevant to a query before outputting that information as part of the search results.
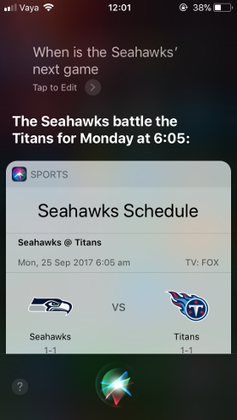
Personal Assistants#
Smartphones with personal assistants like Apple Siri or Google Assistant also rely heavily on machine learning.
 |
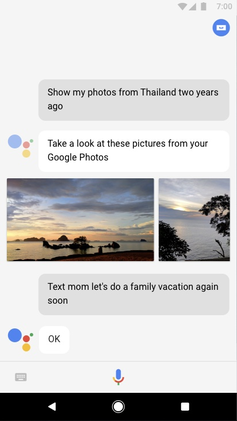 |
The assistant software uses speech recognition algorithms powered by ML to transform the sound of your voice into a sequence of characters or words. It then uses a different set of ML algorithms to infer the intent of your command as well as to perform the processing needed to compute the correct response (in the above example, finding images from Thailand).
Spam and Fraud Detection#
Machine learning helps keep your inbox clean and spam-free. Email software uses classification algorithms to identify spam and non-spam email.
More generally, financial companies rely on ML to flag potentially fraudulent transaction. Machine learning is one reason for why your credit card account is relatively safe from fraud!
Autonomous Vehicles#
Our final example is farther out in the future than the others. Most autonomous vehicles under development today rely on various forms of machine learning to detect objects on the road, read signs, and to plan their movements.

When widely deployed, autonomous vehicles have the potential to transform transportation by reducing its cost and giving access to personal mobility to persons who would otherwise not be able to operate a vehicle (e.g., the blind).
1.1.2. A Definition of Machine Learning#
We have seen a few examples of what machine learning is. Let’s now try to define it formally. We will start with the following definition, first proposed by the Arthur Samuel in 1959.
Machine learning is a field of study that gives computers the ability to learn without being explicitly programmed.
This definition is used in numerous courses and textbooks. At first, it might be hard to grasp what Samuel means by terms like “learn” and “explicitly programmed”. Let’s look at one final example to clarify this.
Self Driving Cars: A Rules-Based System#
We return to our previous example: autonomous vehicles. A self-driving car uses dozens of components based on machine learning. One such component is object detection: given input from the car’s sensors, we want to automatically identify cars, cyclists, pedestrians, and other objects on the road.

How might we build an object detection systems for a car? The classical programming approach is to write down a set of rules.

For example, if we see an object, and it has two wheels, then it is likely to be a bicycle. We can incorporate this logic as one of the rules implemented by our system.
However, in the above image, some cars are seen by the camera from the back. In such cases, cars also appear to have two wheels! In a rules-based system, we need to write an exception to our earlier rule to handle objects seen from the back. Below is pseudocode that tries to implement this idea.
# pseudocode example for a rule-based classification system
object = camera.get_object() # assumes we have a "camera" API
if object.has_wheels(): # does the object have wheels?
if len(object.wheels) == 4: return "Car" # four wheels => car
elif len(object.wheels) == 2:,
if object.seen_from_back():
return "Car" # viewed from back, car has 2 wheels
else:
return "Bicycle" # normally, 2 wheels => bicycle
return "Unknown" # no wheels? we don't know what it is
You can probably see that this approach doesn’t scale. Even in this very simple example, we have run into edge cases that simple rules cannot handle. Imagine now how many edge cases we would encounter if we tried to build a rules-based system for all the possible environments that a self-driving car might encounter.
Clearly, it is almost impossible for a human to specify rules for all the scenarios that can arise in autonomous driving. The rules-based solution does not scale.
Self Driving Cars: An ML-Based System#
Machine learning is an alternative approach to building software systems that instead tries to teach a computer how to perform tasks by providing it examples of desired behavior.
In this example, we might collect a large dataset of labeled objects on the road. We then feed this dataset to a short meta-algorithm through which the computer automatically learns what a cyclist or a car look like. It then uses this knowledge to detect new objects on the road.
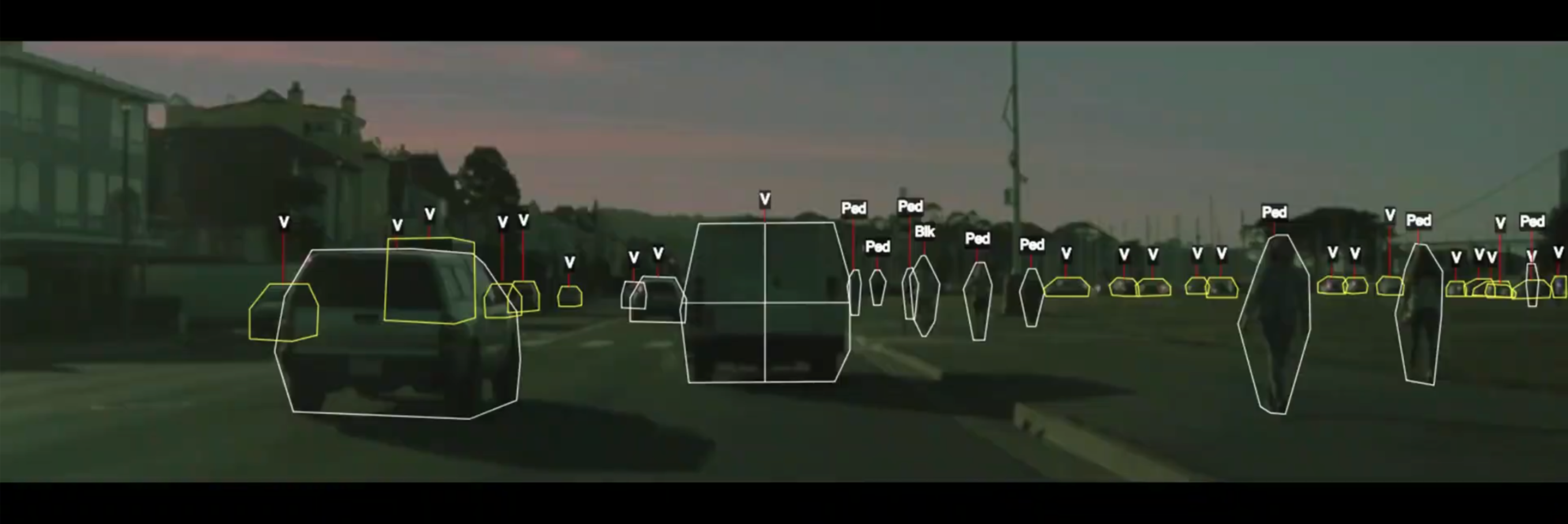
This approach is much more scalable: we no longer need to directly specify the correct behavior for every possible image frame—the computer learns the desired behavior from data.
Revisiting Our Definition of ML#
This example should now help us better understand the definition proposed by Arthur Samuel.
Machine learning is a way of building software systems without explicitly programming their behavior: instead computers can learn to perform the desired behavior on their own from a small number of examples. This principle can be applied to countless domains: medical diagnosis, factory automation, machine translation, and many others.
1.1.3. Why Machine Learning?#
We end this part of the lecture with some final thoughts on the reasons on why you should study machine learning.
First, machine learning is the only way of building certain kinds of software. Object detection is one example, but machine learning also produces the best performing systems for a wide range of tasks such as machine translation, speech recognition, image classification, and many others.
Learning is also widely regarded as a key approach towards building general-purpose artificial intelligence. By developing learning algorithms, we create techniques that may one day enable us to create true AI.
Lastly, machine learning can offer insights into human intelligence. By studying artificial systems, we can also make discoveries about the human mind.
1.2. Three Approaches to Machine Learning#
It is common to define three broad subfields of machine learning which implement three different approaches for creating learning algorithms.
1.2.1. Supervised Learning#
The most common type of machine learning is supervised learning. Most of our previous examples have been instances of this approach.
Supervised learning implements the following strategy:
First, we collect a dataset of labeled training examples.
We teach a model to output accurate predictions on this dataset.
When the model sees new, similar data, it will also be accurate.
In addition to many examples introduced earlier, supervised learning is widely used for tasks such as:
Classifying medical images. Given a large datasets of images of malignant and benign tumors, we seek to develop a system that can identify tumors in new images.
Translating between pairs of languages. Here, supervision comes in the form of pairs of sentences that have the same meaning in two different languages.
Detecting objects in a self-driving car. We provide the model with examples of cars, pedestrians, etc.
1.2.2. Unsupervised Learning#
In unsupervised learning, we start with a dataset that does not contain any labels. Unsupervised learning seeks to discover interesting and useful patterns in this data, such as:
Clusters of related datapoints. For example, we might want to discover groups of similar customers from the logs of an e-commerce website.
Outliers, i.e., particularly unusual or interesting datapoints. For example, suspicious financial transactions.
Denoised signals. Recovering an image corrupted with white noise.
An Example of Unsupervised Learning#
Let’s look more closely at one common real-world application of unsupervised learning. Consider the following text, which contains at least four distinct topics. (image credit: David Blei)
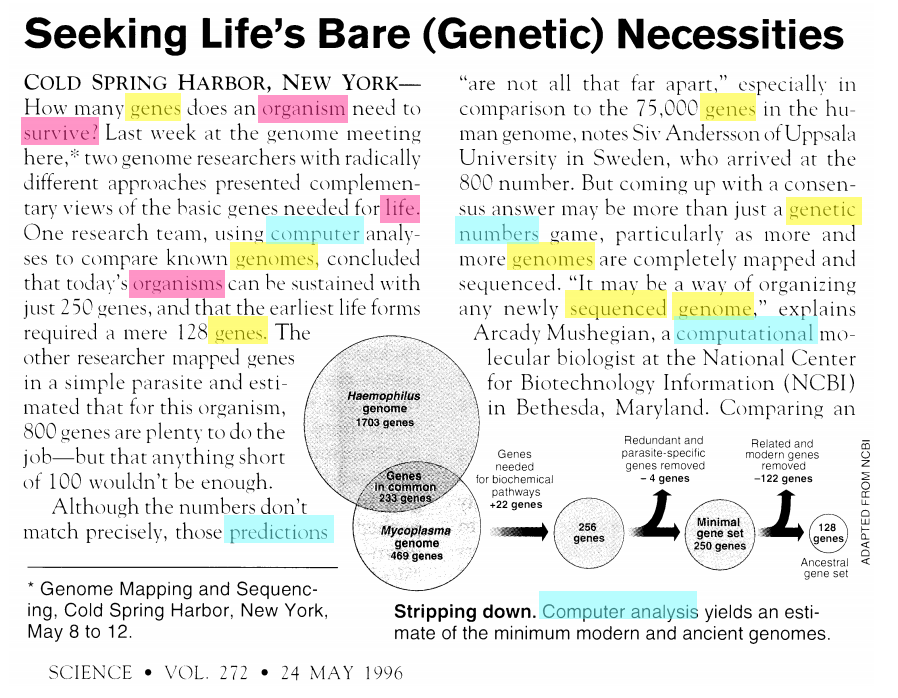
The blue words pertain mostly to computers. The red words pertain to biology. The yellow words are related to genetics.
It would be useful to be able to detect these topics automatically. However, in practice we rarely have access to text in which each word is labeled with a topic.
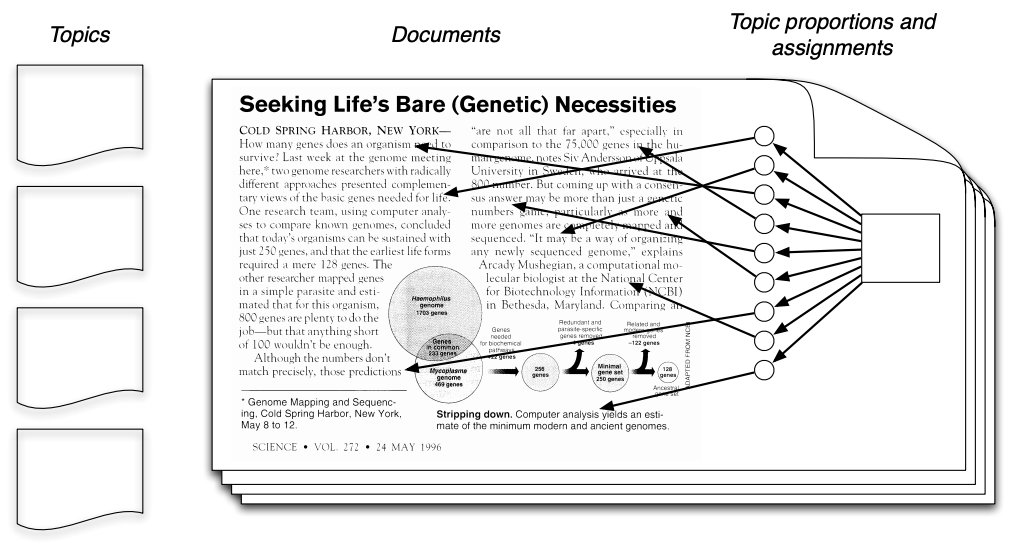
Unsupervised topic models automatically discover clusters of related words (these are the “topics”, e.g., computers) and assign a topic to each word, as well as a set of topic proportions to each document.
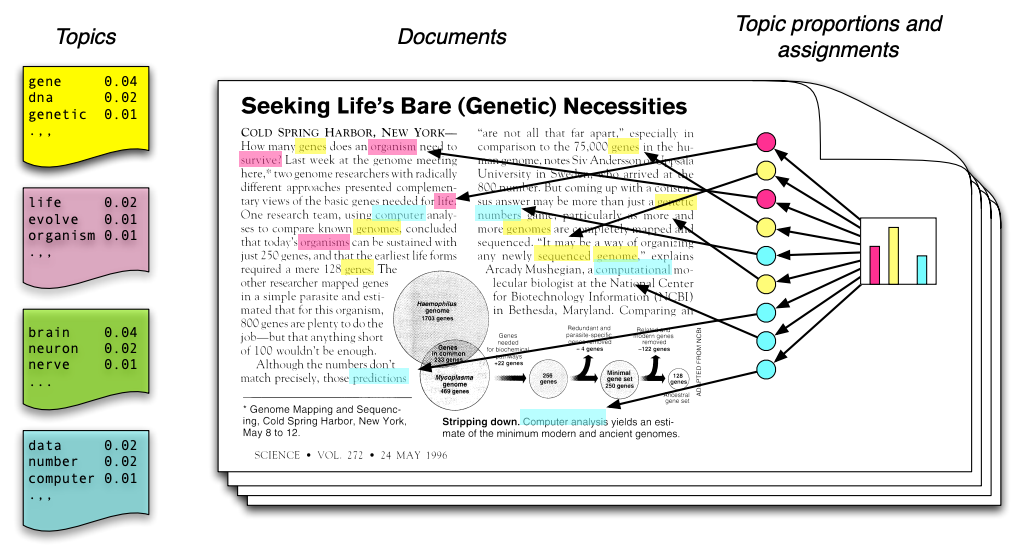
This kind of analysis can be useful for automating research in the social sciences, as well as for accelerating the analysis of financial documents. One of the most well-known topic modeling methods is called latent Dirichlet allocation.
Other Applications of Unsupervised Learning#
Unsupervised learning has numerous other applications:
Recommendation systems. For example, the recommendation engine at Netflix is based on the unsupervised discovery of common viewing patterns across users.
Anomaly detection. The field of predictive maintenance seeks to identify factory components that are likely to fail soon.
Signal denoising. Extracting human speech from a noisy audio recording.
1.2.3. Reinforcement Learning#
In reinforcement learning, an agent is interacting with the world over time. We teach it good behavior by providing it with rewards.
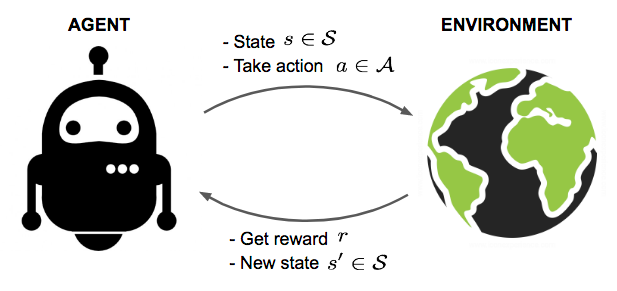
Image by Lily Weng
For example, we may deploy a robot in a real or simulated environment. If the robot executes bad actions (e.g., it breaks something), we provide it with a negative reward. If it performs a useful action (correctly picking up an object), we provide it with a positive reward. The learning algorithm learns over time to perform actions that lead to high reward.
At first, reinforcement learning may appear to be similar to supervised learning. However, the key difference is that in reinforcement learning, an agent must explore the environment and try things on its own to collect rewards (this is called exploration); in supervised learning, all the supervision is provided to the agent upfront.
Applications of Reinforcement Learning#
Applications of reinforcement learning include:
Creating agents that play games such as Chess or Go.
Industrial control: automatically operating cooling systems in datacenters to use energy more efficiently.
Generative design of new drug compounds.
1.2.4 Artificial Intelligence and Deep Learning#
Lastly, machine learning is often discussed in the context of two other related fields : artificial intelligence and deep learning. Their relationship is best described by the Venn diagram below.
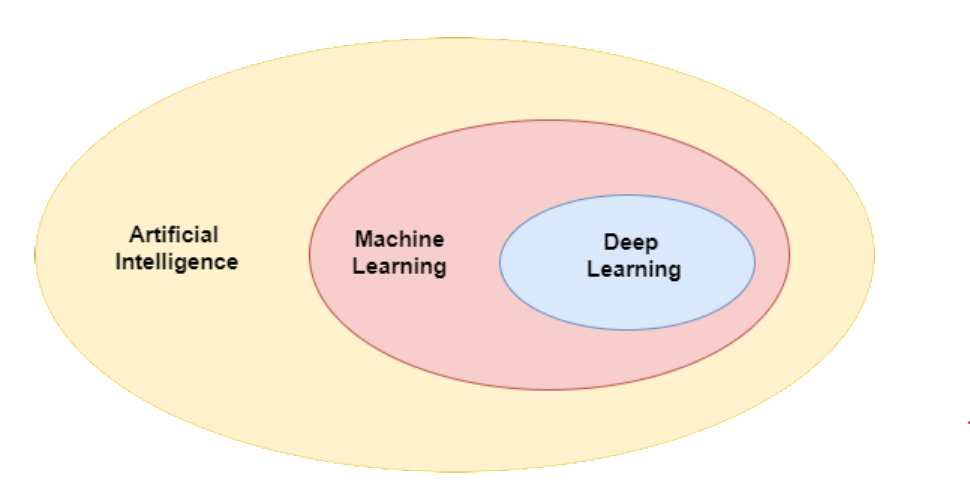
Image source.
The field of AI is concerned with building machines that exhibit human-level intelligence. ML enables machines to learn from experience, which is a useful approach towards this goal. Thus, ML is a subfield of AI.
Deep learning is a field that studies learning algorithms called neural networks that are loosely inspired by the brain. It is a subfield of machine learning.
1.3. Logistics and Course Information.#
We conclude the lecture with the logistical aspects of the course.
1.3.1. What Is the Course About?#
This course studies the foundations and applications of machine learning.
Algorithms: We cover a broad set of ML algorithms: linear models, boosted decision trees, neural networks, SVMs, etc.
Foundations: We explain why they work using math. We cover maximum likelihood, generalization, regularization, etc.
Implementation: We teach how to implement algorithms from scratch using
numpyorsklearn
We also cover many practical aspects of applying machine learning.
Some of the most important sets of topics we will cover include:
Basics of Supervised Learning: Regression, classification, overfitting, regularization, generative vs. discriminative models
Unsupervised Learning: Clustering, dimensionality reduction, etc.
Advanced Supervised Learning: Support vector machines, kernel methods, decision trees, boosting, deep learning.
Applying ML: Overfitting, error analysis, learning curves, etc.
The format of this course will be that of the “reverse classroom”. Pre-recorded lecture videos will be made available online ahead of time. You should watch them ahead of each weekly lecture. In-class discussions will focus on answering student questions, going over homework problems, doing tutorials.
1.3.2. Prerequisites: Is This Course For You?#
The main requirements for this course are:
Programming: At least 1 year of experience, preferably in Python.
Linear Algebra: College-level familiarity with matrix operations, eigenvectors, the SVD, vector and matrix norms, etc.
Probability. College-level understanding of probability distributions, random variables, Bayes’ rule, etc.
This course does not assume any prior ML experience.
1.3.3. Course Materials#
The slides for each lecture are available online on Github.
Detailed lecture notes are available online as an HTML website.
Lecture videos are available on Youtube. These videos were originally recorded for the 2020 edition of the course.
Executable Course Materials#
The core materials for this course (including the slides!) are created using Jupyter notebooks.
We are going to embed an execute code directly in the slides and use that to demonstrate algorithms.
These slides can be downloaded locally and all the code can be reproduced.
Below is an example, where use some standard Python ML libraries to solve a digit classification task.
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, neural_network
plt.rcParams['figure.figsize'] = [12, 4]
We can use these libraries to load a simple datasets of handwritten digits.
# https://scikit-learn.org/stable/auto_examples/classification/plot_digits_classification.html
# load the digits dataset
digits = datasets.load_digits()
# The data that we are interested in is made of 8x8 images of digits, let's
# have a look at the first 4 images.
_, axes = plt.subplots(1, 4)
images_and_labels = list(zip(digits.images, digits.target))
for ax, (image, label) in zip(axes, images_and_labels[:4]):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title('Label: %i' % label)
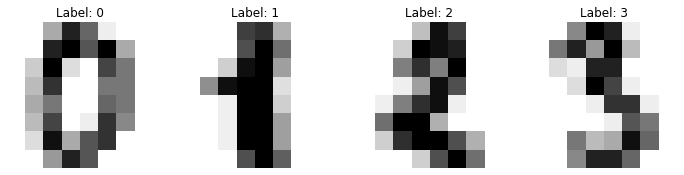
We can now load and train this algorithm inside the slides.
np.random.seed(0)
# To apply a classifier on this data, we need to flatten the image, to
# turn the data in a (samples, feature) matrix:
data = digits.images.reshape((len(digits.images), -1))
# create a small neural network classifier
from sklearn.neural_network import MLPClassifier
classifier = MLPClassifier(alpha=1e-3)
# Split data into train and test subsets
X_train, X_test, y_train, y_test = sk.model_selection.train_test_split(data, digits.target, test_size=0.5, shuffle=False)
# We learn the digits on the first half of the digits
classifier.fit(X_train, y_train)
# Now predict the value of the digit on the second half:
predicted = classifier.predict(X_test)
We can now visualize the results.
_, axes = plt.subplots(1, 4)
images_and_predictions = list(zip(digits.images[n_samples // 2:], predicted))
for ax, (image, prediction) in zip(axes, images_and_predictions[:4]):
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title('Prediction: %i' % prediction)